# 一. 基础
- 定义:
- 链表通常由一连串节点(“链结点”)组成,每个节点包含任意的实例数据(data fields)和一或两个用来指向上一个/或下一个节点的位置的链接(“links”)。
- 链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。
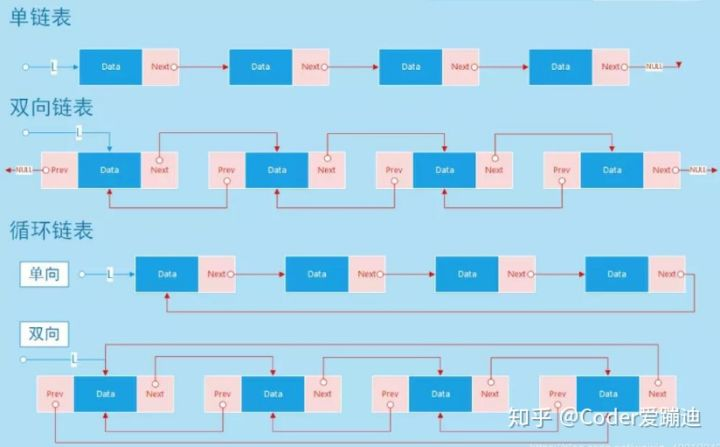
- 链表包含了单链表,双向链表,单项循环链表,双向循环链表在磁盘中的存储不是一段连续的地址空间,而是分开存储的。
- 单链表只记叙了数据(Date)和下一个节点(next)的存储位置。
- 双向链表(Double Linked List)在数据的前后,分别给出了前一个数据节点的存储位置和后一个数据节点的存储位置。
- 单向循环链表(Circular Linked List)和双向链表基本相同,不同的是,在循环链表中的开始节点的前一个数据节点指向最后一个数据节点的存储位置,最后一个数据节点的下一个数据节点指向开始节点的存储位置。
- 双向循环链表 [Double Circular Linked List] : 由各个内存结构通过指针 Next 和指针 Prev 链接在一起组成,每一个内存结构都存在前驱内存结构和后继内存结构,内存结构由数据域、Prev 指针域和 Next 指针域组成。
- 链表的插入删除效率非常高,在插入元素时,只需要将插入位置的前一个节点的位置指向,赋值为插入的数据的位置,然后将插入数据的下一个节点指向后一个数据的存储位置即可。删除时,只需要修改删除位置的前后节点指向即可,将前一个节点的指向修改为要删除元素的后一个节点的存储位置。如果是双向链表,再将删除节点的后一个节点的指向修改为删除元素之前的节点的存储位置。
# 二. 刷题
多画图
- 在链表刷题中,有一些常见的命名
cur:当前节点指针
pre,rear:前后节点指针
fast,slow:快慢指针
next:指向下一个节点的指针域
head,tail:头尾节点指针
dummy:哨兵、虚拟头结点
val:值
ListNode: 链表节点
技巧点 (1)基本:找到递归结束条件,找到递归的式子
看文章 链表原来如斯简单:https://www.pzijun.cn/algorithms/list/1.html#%E5%BC%95%E8%A8%80
(1)删除链表倒数第 n 个结点 走了 n 步:从头结点开始算一步
- 看清楚题目要求返回的数据;输出该节点与输出头结点的不同操作
//比如,要求返回的是ListNode
/**
* @param {ListNode} head
* @return {ListNode}
*/
let node=head
...
node=node.cur
...
return node//输入该节点
return head//输出头结点
2
3
4
5
6
7
8
9
10
11
12
# 三. 头指针
# 1. 定义
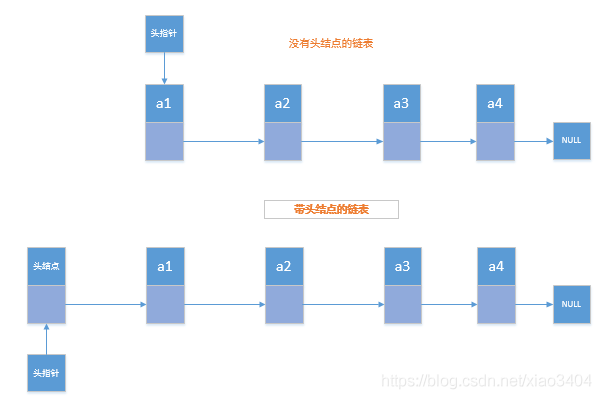
辨析线性表的插入删除需要移动大量的元素,因此引入链表(本文讨论单链表)的概念,链表元素之间通过“链”来链接,因此插入和删除时不需要大量的移动元素,而只需要改变“链”的关系即可。头指针:通常使用“头指针”来标识一个链表,如单链表 L,头指针为 NULL 的时表示一个空链表。链表非空时,头指针指向的是第一个结点的存储位置。头结点:在单链表的第一个结点之前附加一个结点,称为头结点。头结点的 Data 域可以不设任何信息,也可以记录表长等相关信息。若链表是带有头结点的,则头指针指向头结点的存储位置。[注意]无论是否有头结点,头指针始终指向链表的第一个结点。如果有头结点,头指针就指向头结点。
# 2. 引入头结点的优势优势
优势 1:第 1 个位置的插入、删除更加方便,带来操作上的统一
(1)插入
带头结点:
例如:head 为头指针,x 待插入(后插方式)的新结点,p 为指向任意结点的指针。
//p = head;
x->next = head->next;
head->next = x;
//插入其他结点
x->next = p->next;
p->next = x;
2
3
4
5
6
若令 p=head,则带有头结点的链表,可以实现代码复用,减少分支。
不带头结点:
x->next = head;
head = x;
//插入其他结点
x->next = p->next;
p->next = x;
2
3
4
5
因此,不带头结点的链表,插入第一个结点时,需要特殊处理,删除操作类似。
(2)删除
带头结点:
- p 指向要删除结点的前驱结点,若要删除的结点为第 1 个位置,则其前驱结点就是头结点,此时 p 指向头结点。
- 让临时指针 q 指向要删除的结点,即 q = p—>next;
- 让 p 的 next 指向要删除结点的下一个结点,即 p—>next = q—>next;
- 释放 q 的空间,即 free(q);
不带头结点:
- 判断要删除的是否是第 1 个位置,若是需要特殊处理。
- 若是第 1 个位置,让 s 指向要删除的结点。首先判断 PtrL 是否为空,若是直接 return NULL;若不为空,则将链表的头结点挪到下一个位置,即 PtrL = PtrL—>next;
- free(s);然后 return PtrL
- 若不是第 1 个位置,首先找到要删除结点的前驱结点,让 p 指向这个前驱结点。
- 让临时指针 q 指向要删除的结点,即 q = p—>next;
- 让 p 的 next 指向要删除结点的下一个结点,即 p—>next = q—>next;
- 释放 q 的空间,即 free(q);
- return PtrL
优势 2:统一空表和非空表的处理
若使用头结点,无论表是否为空,头指针都指向头结点,也就是*LNode类型,对于空表和非空表的操作是一致的。
若不使用头结点,当表非空时,头指针指向第 1 个结点的地址,即*LNode类型,但是对于空表,头指针指向的是 NULL,此时空表和非空表的操作是不一致的。所以单链表一般为带头结点的单链表。
# 参考
[1] http://t.csdn.cn/hzA1D
[2] https://leetcode-cn.com/circle/article/3lwAea/
[3] https://www.pzijun.cn/algorithms/list/1.html#%E5%BC%95%E8%A8%80